R Language
그래픽 예제 뜯어보기
지난 포스팅을 나열해 드리겠습니다.
[IT/R] - R언어 | Part_1 R 다운로드 및 맛보기
[IT/R] - R언어 | Part_2 차근차근 그래픽 예제 뜯어보기 1
[IT/R] - R언어 | Part_3 차근차근 그래픽 예제 뜯어보기 2
[IT/R] - R언어 | Part_4 차근차근 그래픽 예제 뜯어보기 3
인공지능
빅데이터
머신러닝
딥러닝
4차 산업혁명
꼬리표를 또 달고
R언어 포스팅을 시작하겠습니다.
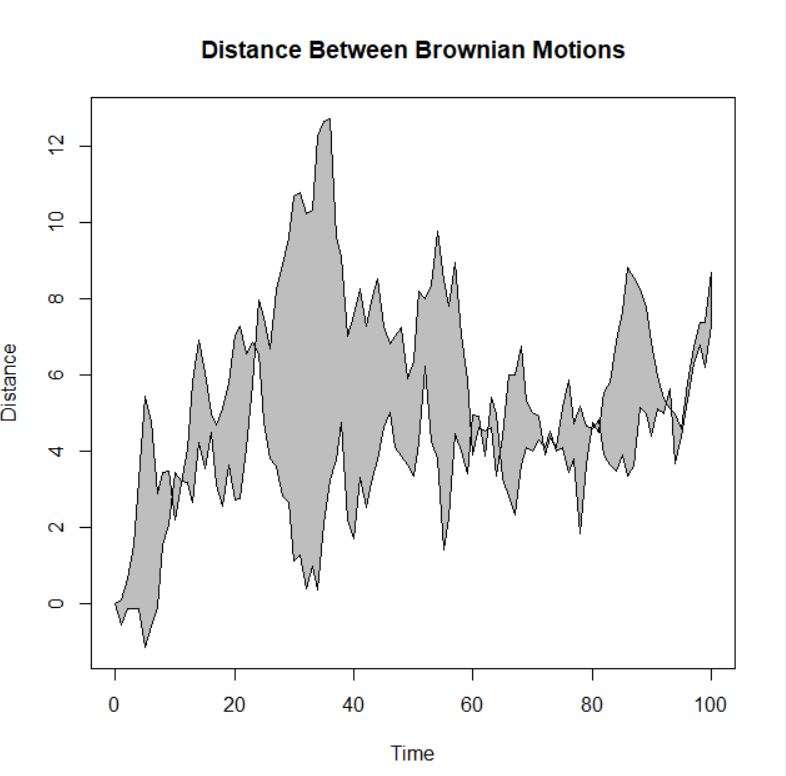
이번에는 polygon을 사용하여
그래프를 그려 보겠습니다.
polygon은 다각형, 각진 도형을 의미합니다.
폴리곤
어디서 많이 들어봤는데요
폴리곤이라 불리는 이 친구도
입체 다각형들의 집합입니다.
다각형 모양의 그래프는
점들의 연결으로 선이 생기는데
다른 두 종류의 선 사이를 칠하면
다각형의 모양이 나오게 됩니다.
이번에도 demo함수를 사용하여
진행하겠습니다.
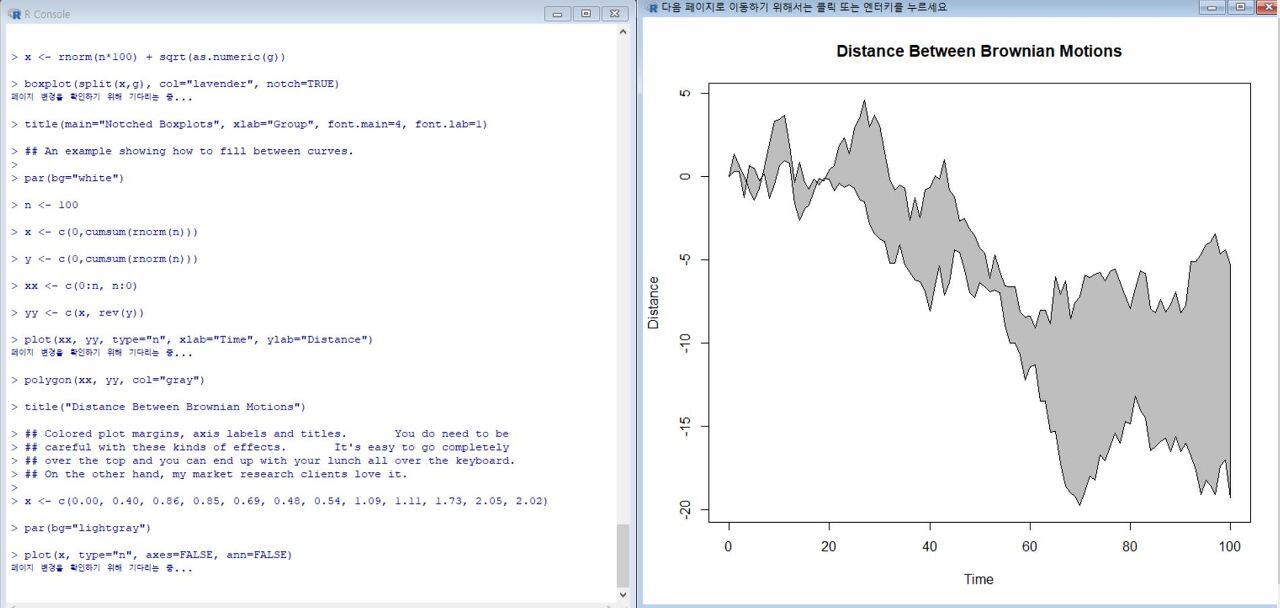
아래는 전체 소스코드 입니다.
par(bg="white") n <- 100 x <- c(0,cumsum(rnorm(n))) y <- c(0,cumsum(rnorm(n))) xx <- c(0:n, n:0) yy <- c(x, rev(y)) plot(xx, yy, type="n", xlab="Time", ylab="Distance") polygon(xx, yy, col="gray") title("Distance Between Brownian Motions")
이번에도 한줄씩 한줄씩
실행을 해 보시고
어떤 순서로 어떻게 생성되는지
알아보시기 바랍니다.
par(bg="white")
먼저 배경색을 흰색으로 만들어 줍니다.
n <- 100
n에 100을 저장해 주고,
x <- c(0,cumsum(rnorm(n)))
n(100)개의 정규분포 난수를 생성하여 (참조 :[IT/R] - R언어 | Part_2 차근차근 그래픽 예제 뜯어보기 1)
누적합을 x에 넣어줍니다.
cumsum은 누적합을 구하는 함수입니다.
0이 들어가는 이유는
첫번째 인자부터
더해진 값이 들어가기 때문에 넣습니다.
예를들어
아래 그림과 같이 qq에 1 2 3 4 5 를 넣고
cumsum (누적합)을 해 주시면
1 3 6 10 15의 값이 나온걸 확인하실 수 있습니다.
따라서 앞에 0을 넣어 0 1 3 6 10 15 순서로
배열을 넣어주었다 생각하시면 됩니다.

y <- c(0,cumsum(rnorm(n)))
이전과 똑같이 정규분포 난수의 누적합을 y에 넣어줍니다.
xx <- c(0:n, n:0)
xx에 0부터 n까지(100),
그리고 n(100)부터 0까지의 배열을
넣어줍니다.
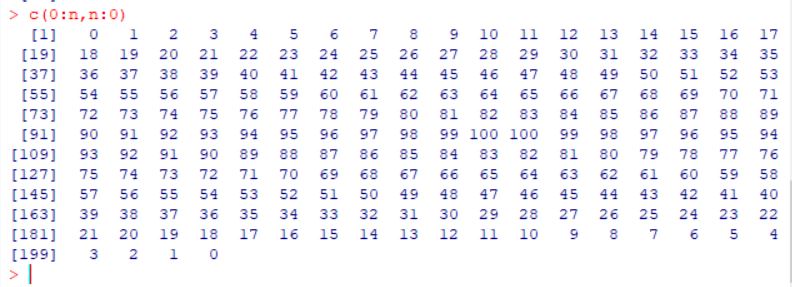
yy <- c(x, rev(y))
y값 배열의 역순을 yy에 저장해 줍니다.
rev는 reverse의 약자라고 보시면 됩니다.
아래와 같이 배열의 순서가 역순으로 됩니다.

plot(xx, yy, type="n", xlab="Time", ylab="Distance")
x,y축으로 이루어진 그래프를 만듭니다.
type="n"이므로 좌표를 찍지 않고 (참고 :[IT/R] - R언어 | Part_2 차근차근 그래픽 예제 뜯어보기 1)
x축과 y축의 제목을 넣어줍니다.
polygon(xx, yy, col="gray")
xx와 yy값의 좌표를 가지고 polygon. 즉 다각형의 그래프를 그립니다.
col처럼 여기도 다양한 옵션을 넣을 수 있습니다.
x, y -> 좌표
col -> 색상
lty -> 선 종류
lwd -> 선 굵기
density -> 선의 밀도
angle -> 선의 기울기
title("Distance Between Brownian Motions")
제목을 넣어줌으로 그래프를 완성합니다.
곧이어 다음 포스팅에서는
가로 막대 그래프를 해보겠습니다.
감사합니다.
'IT > R' 카테고리의 다른 글
| R언어 | Part_4 차근차근 그래픽 예제 뜯어보기 3 (0) | 2020.09.20 |
|---|---|
| R언어 | Part_3 차근차근 그래픽 예제 뜯어보기 2 (0) | 2020.09.19 |
| R언어 | Part_2 차근차근 그래픽 예제 뜯어보기 1 (0) | 2020.09.17 |
| R언어 | Part_1 R 다운로드 및 맛보기 (0) | 2020.09.16 |