R Language 그래픽 예제 뜯어보기
지난 포스팅은 아래와 같습니다.
[IT/R] - R언어 | Part_1 R 다운로드 및 맛보기
[IT/R] - R언어 | Part_2 차근차근 그래픽 예제 뜯어보기 1
지난 포스팅에 이어
인공지능
빅데이터
머신러닝
딥러닝
4차 산업혁명
꼬리표를 또 달고
R언어 포스팅을 시작하겠습니다.
이번에 보실 예제는
pie( ) 함수가 주가 되어
파이차트 , 원형차트를 사용해
실습을 진행하겠습니다.
저번 포스팅과 같이 데모 를 사용하여
두번째 예제를 활용하여 진행하겠습니다.
전체 코드입니다.
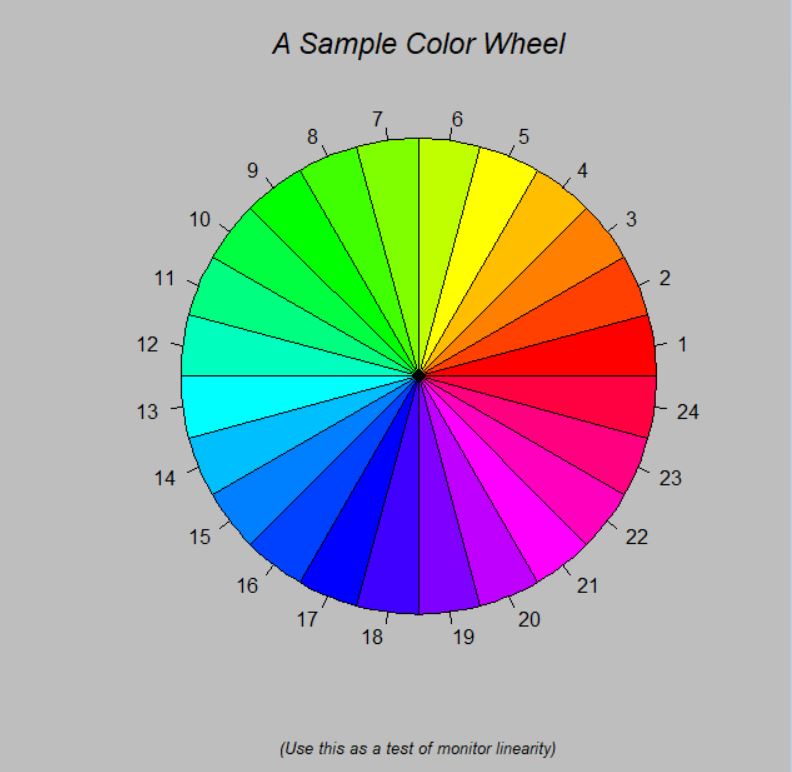
par(bg = "gray") pie(rep(1,24), col = rainbow(24), radius = 0.9) title(main = "A Sample Color Wheel", cex.main = 1.4, font.main = 3) title(xlab = "(Use this as a test of monitor linearity)", cex.lab = 0.8, font.lab = 3)
이번에도
한줄씩 한줄씩 실행을 먼저 해 보시고
아래 코드를 보시면 될 것 같습니다.
par(bg = "gray")
배경색을 회색으로 하여 틀을 만들어 줍니다.
pie(rep(1,24), col = rainbow(24), radius = 0.9)
파이차트를 생성합니다.
pie( x , types ) 이렇게 사용 하는데,
rep(1,24) = c(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1) 처럼
동일 하다 생각하시면 됩니다.
즉, 이렇게 사용 하셔도 됩니다.
xvalue <- c(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1)
pie( xvalue, types )
여기엔 다양한 옵션 들을 넣을 수 있는데,
col -> 색상
radius -> 파이차트 크기
density -> 밀집도 (수)
angle -> 각도
clockwise -> 방향 ( T = 시계방향(default값) , F = 반시계방향 )
등이 있습니다.
위 숫자를 좀 더 변형 시켜서
이렇게 실행을 한다면 아래와 같은 결과를 보실 수 있습니다.
pie(rep(1,200), col = rainbow(200), radius = 1.0)
title(main = "A Sample Color Wheel", cex.main = 1.4, font.main = 3)
A Sample Color Wheel 이라는 제목을 주고 도형 및 글자 크기를 설정합니다.
title(xlab = "(Use this as a test of monitor linearity)", cex.lab = 0.8, font.lab = 3)
마찬가지로 x축 제목 및 도형, 글자 크기를 설정해 줍니다.
다음 예제 는
다양한 값의 크기를 가진 데이터들과
그 데이터에 이름을 붙여
전형적인 원형차트 로 보실 수 있습니다.
다음 예제의 전체 코드입니다.
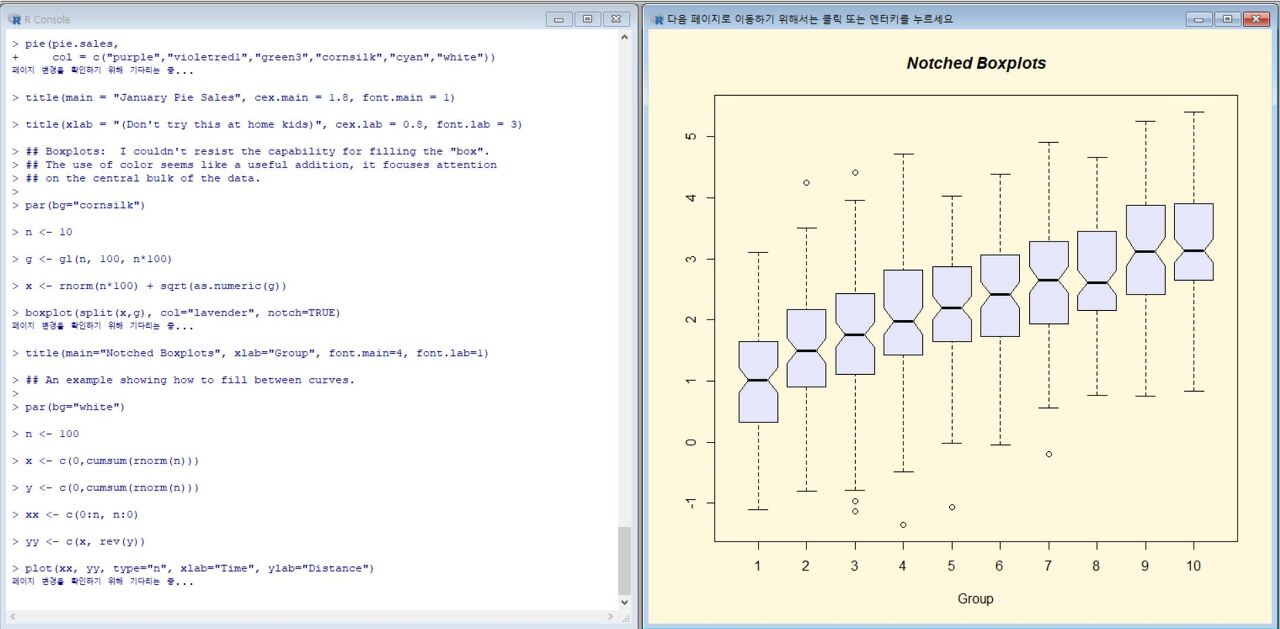
pie.sales <- c(0.12, 0.3, 0.26, 0.16, 0.04, 0.12) names(pie.sales) <- c("Blueberry", "Cherry", "Apple", "Boston Cream", "Other", "Vanilla Cream") pie(pie.sales, col = c("purple","violetred1","green3","cornsilk","cyan","white")) title(main = "January Pie Sales", cex.main = 1.8, font.main = 1) title(xlab = "(Don't try this at home kids)", cex.lab = 0.8, font.lab = 3)
pie.sales <- c(0.12, 0.3, 0.26, 0.16, 0.04, 0.12)
먼저 pie.sales라는 이름을 가진 벡터 변수 를 생성해 줍니다.
names(pie.sales) <- c("Blueberry", "Cherry", "Apple", "Boston Cream", "Other", "Vanilla Cream")
각각의 벡터값에 이름 을 붙여줍니다.
pie(pie.sales, col = c("purple","violetred1","green3","cornsilk","cyan","white"))
pie.sales를 사용하여 파이차트 를 생성 해 줍니다.
위의 RGB 예제에서는
pie(x, types)의 x값에 모두 1이 들어가서
파이차트의 각각의 데이터 크기가 같았습니다.
이번에는 pie.sales의 다양한 값 을 사용하여
각각 다른 크기의 데이터를 가진
파이차트를 만듭니다.
title(main = "January Pie Sales", cex.main = 1.8, font.main = 1)
January Pie Sales라는 제목을 주고 도형 및 글자의 크기를 설정해 줍니다.
title(xlab = "(Don't try this at home kids)", cex.lab = 0.8, font.lab = 3)
마지막으로 x축에도 이름을 주고 도형 및 글자 크기를 설정해 줍니다.
* 배경색은 따로 지정하지 않으셨다면 흰색으로 나타날 겁니다.
이로써 정말 간단한 몇줄 로
파이차트(원형차트) 를 만들어 보았습니다.
다음 포스팅에서는 다양한 모양의 그래프를
만들어 보는 실습을 하며
추후 일차적인 목적은
지리정보공간시스템(GIS) 을
실습해 보는것으로 하겠습니다.
감사합니다.